Junxuan Bai
白隽瑄
Sports × AI × VR/AR
Bridging Computer Graphics and Sports Science through Immersive Intelligence
Research Affiliate
Institute of Artificial Intelligence in Sports
Capital University of Physical Education and Sports
 https://orcid.org/0000-0002-7941-0584
https://orcid.org/0000-0002-7941-0584Journal Papers
LiteNeRFAvatar: A lightweight NeRF with local feature learning for dynamic human avatar
Avatar
Junjun Pan, Xiaoyu Li, Junxuan Bai (co-first author), Ju Dai
Pattern Recognition, Volume 170, 2026
[Video]
[Code]
![]()
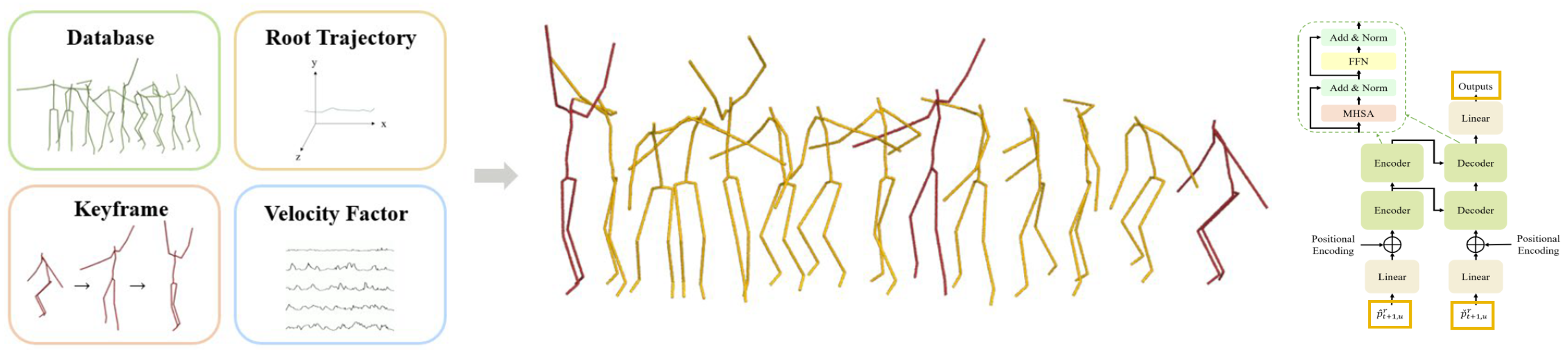
Motion In-Betweening via Recursive Keyframe Prediction
Motion
Animation
Rui Zeng, Ju Dai, Junxuan Bai, Junjun Pan
Computer Animation and Virtual Worlds, 36(3), e70035, 2025

Motion Editing for Quadruped Characters via Latent Frequency Embedding
Motion
Animation
Rui Zeng, Junjun Pan, Ju Dai, Yang Gao, Junxuan Bai, Hong Qin
IEEE Transactions on Visualization and Computer Graphics, 2024

Free Editing of Shape and Texture with Deformable Net for 3D Caricature Generation
Avatar
Yuanyuan Lin, Ju Dai, Junjun Pan, Feng Zhou, Junxuan Bai
The Visual Computer, 2024

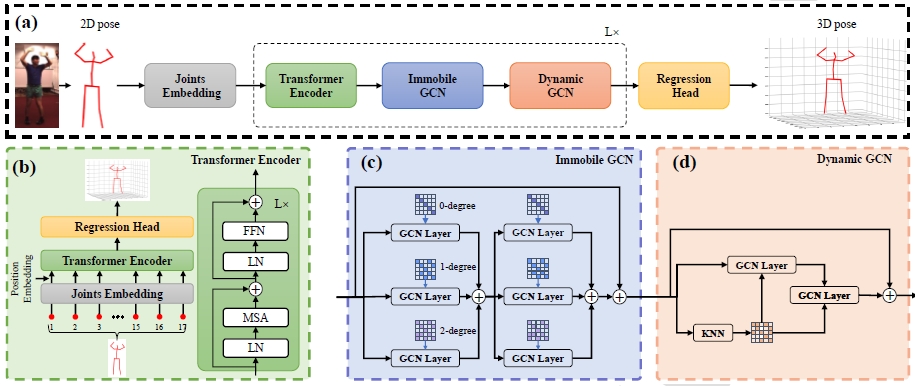
DGFormer: Dynamic graph transformer for 3D human pose estimation
Motion
Zhangmeng Chen, Ju Dai, Junxuan Bai, Junjun Pan
Pattern Recognition, 152, 2024
[Code]
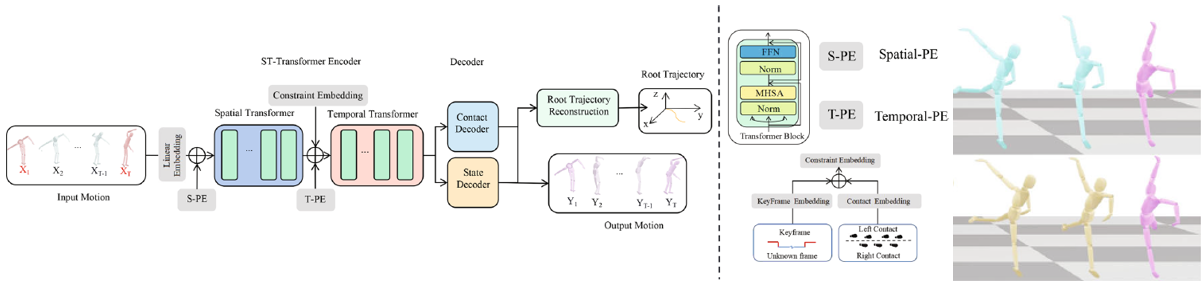
Foot-constrained spatial-temporal transformer for keyframe-based complex motion synthesis
Motion
Animation
Hao Li, Ju Dai, Rui Zeng, Junxuan Bai, Zhangmeng Chen, Junjun Pan
Computer Animation and Virtual Worlds, e2217, 2023.
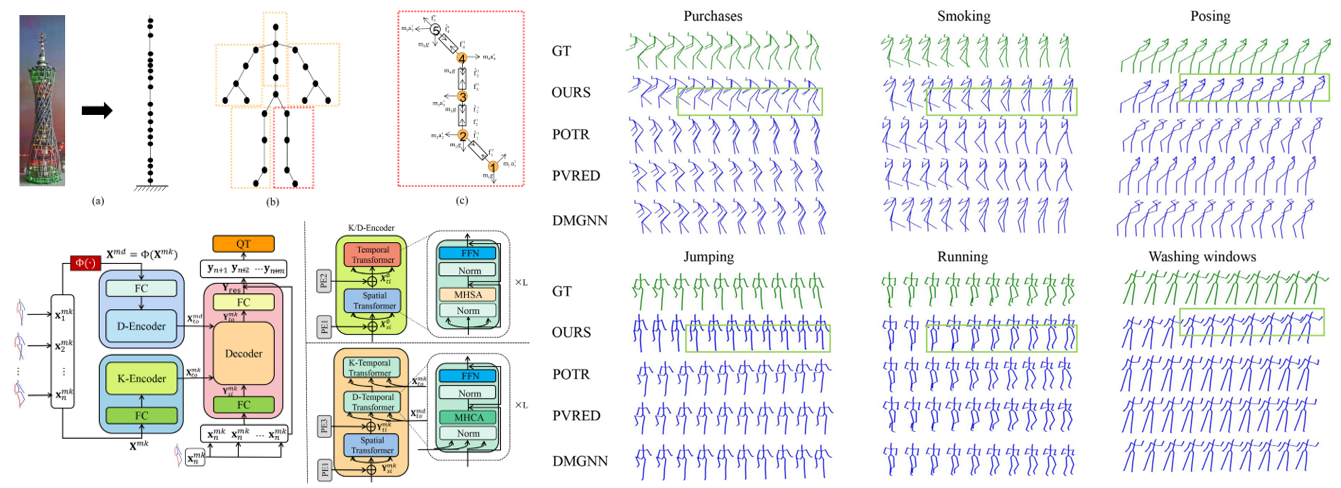
KD-Former: Kinematic and dynamic coupled transformer network for 3D human motion prediction
Motion
Ju Dai, Hao Li, Rui Zeng, Junxuan Bai, Feng Zhou, Junjun Pan
Pattern Recognition, 143, 2023.
[Code]
Diverse Dance Synthesis via Keyframes with Transformer Controllers
Motion
Animation
Junjun Pan, Siyuan Wang, Junxuan Bai, Ju Dai
Computer Graphics Forum, 40(7): 71-83, 2021.
[PDF]
[Slides]
[Presentation]
[Code]
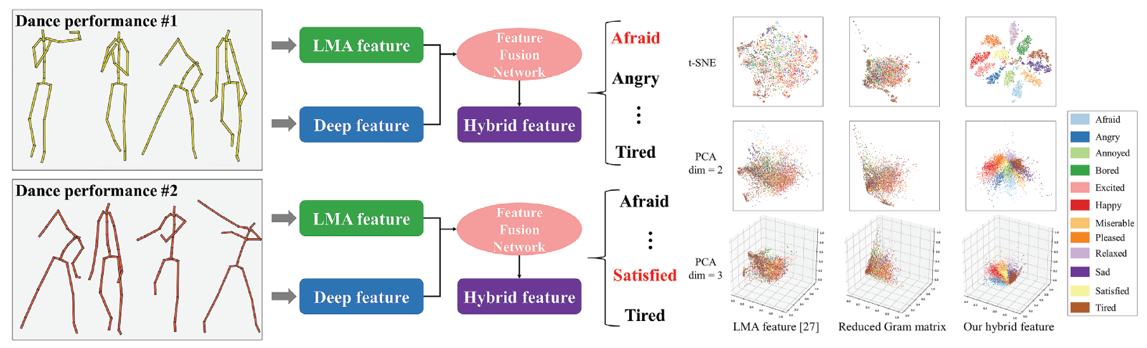
EmoDescriptor: A hybrid feature for emotional classification in dance movements
Motion
Sports-AI
Junxuan Bai, Rong Dai, Ju Dai, and Junjun Pan
Computer Animation and Virtual Worlds, 32(6), 2021.
[PDF]
[Video]
Interactive animation generation of virtual characters using single RGB-D camera
Animation
Immersive
Ning Kang, Junxuan Bai (co-first author), Junjun Pan, and Hong Qin
The Visual Computer, 35(6-8): 849-860, 2019.
[PDF]
[Presentation]

Novel metaballs-driven approach with dynamic constraints for character articulation
Animation
Junxuan Bai, Junjun Pan, Yuhan Yang, and Hong Qin
SCIENCE CHINA Information Science, 61(9): 094101:1-094101:3, 2018.
[PDF]
[Slides]
[Video]
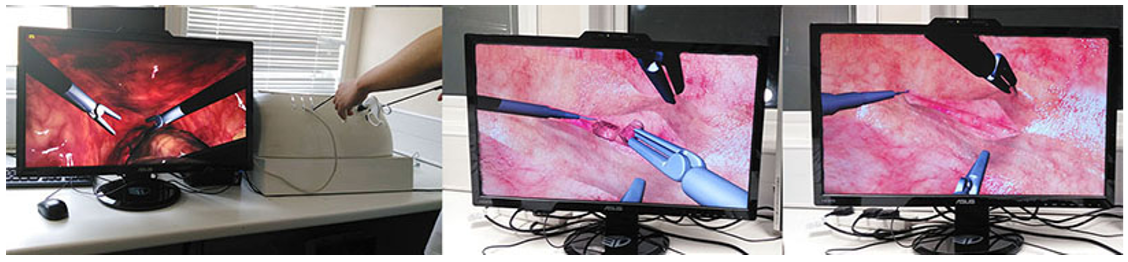
Essential techniques for laparoscopic surgery simulation
Immersive
Medical-VR
Kun Qian, Junxuan Bai, Xiaosong Yang, Junjun Pan, Jian-Jun Zhang
Computer Animation and Virtual Worlds, 28(2), 2017.

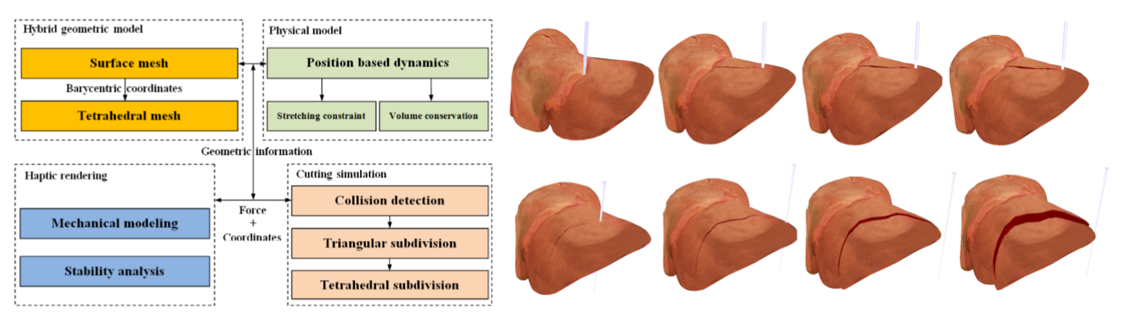
Real-time haptic manipulation and cutting of hybrid soft tissue models by extended position-based dynamics
Immersive
Medical-VR
Junjun Pan, Junxuan Bai, Xin Zhao, Aimin Hao, and Hong Qin
Computer Animation and Virtual Worlds, 26(3-4): 321-335, 2015.
[PDF]

Conference Papers
VIMCAN: Visual-Inertial 3D Human Pose Estimation with Hybrid Mamba-Cross-Attention Network
Motion
Zepeng Yang, Junxuan Bai (co-first author), Hao Li, Ju Dai, Junjun Pan, Yongfeng Yin, Bin Li
CVPR 2026, Poster, 2026
[PDF]
[Video]

BounceCoach: Real-Time Basketball Dribble Training with On-Site Large Language Model Guidance
Immersive
Sports-AI
Ruoyi Zhao, Li Hua, Yixuan Nan, Yiming Wang, Junxuan Bai (joint corresponding author), Jin Li, Feng Zhou
2026 IEEE Conference on Virtual Reality and 3D User Interfaces Abstracts and Workshops (VRW), Poster, 2026
Attribute-Decomposable Motion Compression Network for 3D MoCap Data
Motion
Zengming Chen, Junxuan Bai (co-first author), Ju Dai
Data Compression Conference (DCC) 2022, Full paper, 2022
[PDF]
[Slides]

3D-CariNet: End-to-end 3D caricature generation from natural face images with differentiable renderer
Avatar
Meijia Huang, Ju Dai, Junjun Pan, Junxuan Bai, Hong Qin
Pacific Graphics 2021, Short paper, 2021
[PDF]
Human motion synthesis and control via contextual manifold embedding
Motion
Animation
Rui Zeng, Ju Dai, Junxuan Bai, Junjun Pan, Hong Qin
Pacific Graphics 2021, Short paper, 2021
[PDF]
Flower factory: a component-based approach for rapid flower modeling
Animation
Siyuan Wang, Junjun Pan, Junxuan Bai, Jinglei Wang
ISMAR 2020: 12-23, Conference paper, 2020
[PDF] [Presentation]

Real-time animation and motion retargeting of virtual characters based on single RGB-D camera
Immersive
Animation
Ning Kang, Junxuan Bai, Junjun Pan, Hong Qin
VR 2019: 1006-1007, Poster, 2019
Virtual reality based laparoscopic surgery simulation
Immersive
Medical-VR
Kun Qian, Junxuan Bai, Xiaosong Yang, Junjun Pan, Jian-Jun Zhang
VRST 2015: 321-335, Conference paper, 2015
Dissection of hybrid soft tissue models using position-based dynamics
Immersive
Medical-VR
Junjun Pan, Junxuan Bai, Xin Zhao, Aimin Hao, and Hong Qin
VRST 2014: 219-220, Poster, 2014